”利奇马“来上海了,台风暴雨也是我第一次见识,不过还好今天上海不是中心,风雨都没有那么严重,但是这样的天气倒是让人不想工作,所以一废废到了6点。。。。
扯皮结束
一个页面,从输入URL到页面展示的过程中发生了什么,这个问题在很多面试中都会出现,究其原因,也自然是因为它真的是一个可以全面考察个人基础知识的问题,今天就来仔细分析一下这个问题(只考虑前端和网络的一些问题,后端具体问题不研究
当然,会参考很多网上大佬的结论😬
不过本文不会对其中提到的一些特别细节的东西进行阐述,这么写的话这篇文章就太杂了,细节如果有必要的话会另开一篇文章,TODO 记得把链接链过来
输入地址
当我们开始在地址栏里输入url的时候,浏览器就已经开始匹配了,它们会从 历史记录、书签 等位置寻找可能匹配的url,然后给出智能提示进行补全
更高端的是,类似 chrome 这样的浏览器,甚至会从缓存中把网页展示出来
2. 查找 url 对应的 IP 地址(DNS查询)
在因特网的世界里,每个服务器对应的,都是类似 xxx.xxx.xxx.xxx 这样的IP地址,这个地址对于计算机来说,清晰明了好辨认,但是对于人类而言,没有语义的数字显然不够,所以我们使用 url 对 IP 地址进行代表,那么,这个 url 又是如何转换成 计算机方便辨认的 IP 地址的呢?这里就涉及到了 DNS 查询的过程,主要涉及以下几步(注意,目的是拿到域名对应的IP地址
- 浏览器首先会查看本地的 hosts 文件,看有没有和这个域名对应的规则,如果有的话就可以直接拿到对应的IP地址了,没有的话只能进行下一步。
- 浏览器在本地hosts里没有找到,那么会首先向本地的DNS服务器发起查询请求(本地DNS服务器通常指网络接入服务提供商,比如中国电信、中国移动等),这是一个完全托管的行为,当浏览器向本地DNS服务器发出请求之后,就可以不用管它了,本地DNS服务器会自己处理各种过程,并且把最后查到的 IP 地址返回给浏览器(这里就是一个递归查询的过程)
- 本地DNS服务器接收到查询请求之后,会首先在自己的缓存记录里查找是不是有这样的一个域名记录,如果有的话,就可以直接把 ip 地址返回给浏览器了,如果没有的话,像之前说的,它不会直接向浏览器报告这个结果,而是直接去向 DNS根服务器 进行查询
- DNS根服务器 不会直接记录 具体域名 和 ip地址的对应关系,它记录的是 下一级域名 对应的 DNS 服务器地址(比如像 .com \ .net 这种域名服务器的地址),他会把这个DNS服务器的地址返回给 本地DNS服务器
- 本地DNS服务器收到这个地址之后,向这个 DNS域服务器 发起请求进行查询,而这个 DNS域服务器 存储的也是 下一级域名解析服务器的地址,它会在查询之后把这个地址返回给 本地DNS服务器
- 本地DNS服务器继续向这个 域名的解析服务器 发起请求,这个服务器存储的就是 具体域名的IP地址了,它把这个 IP地址返回给 本地DNS服务器
- 本地DNS服务器接收到这个 IP 地址之后,把这个IP地址返回给浏览器,同时把这个 域名-IP 的映射关系添加到自己的缓存记录中去

浏览器跟本地DNS服务器之间的查询方式,就是一个递归查询的过程,浏览器直接托管本地DNS服务器进行查询
而本地DNS服务器跟其他域名服务器之间的查询过程,就是一个迭代查询的过程了,都是本地DNS服务器再控制
【others】
提一嘴DNS负载均衡:
其实这个过程就是为了避免某个主机由于访问量过大而无法承受的情况,DNS负载均衡就是在DNS服务器中为同一个主机名配置多个IP地址,在应答DNS查询的时候,按照顺序返回不同的IP地址的主机,将客户端的访问引导到不同的机器上去
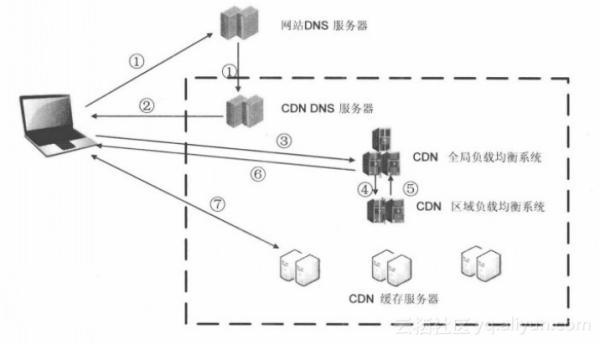
更复杂一点的情况,会在这里用到CDN来降低由于服务器性能、服务器分布、网络带宽带来的时延。过程:
在这里的最后一级域名服务器,返回的不是 请求资源的主机,而是交给CNAME指向的CDN专用DNS服务器,这个CDN的域名服务器会把CDN的全局负载均衡设备IP地址 返回给用户
用户向这个 全局负载均衡设备发起请求
全局负载均衡设备 根据用户所请求资源的内容,以及用户的IP地址,选择一台用户所属区域的 局域CDN负载均衡设备,告诉用户向这个地址发起请求
区域CDN负载均衡设备 会为用户选择一个合适的缓存服务器提供服务,选择的依据包括:
- 根据用户IP地址判断 距离较近的 缓存服务器
- 根据用户所请求的内容,判断哪个服务器上可以提供
- 查询各缓存服务器的当前负载情况,判断谁还有余力
然后把这个缓存服务器的地址返回给 全局CDN负载均衡设备
全局CDN负载均衡设备把这个缓存服务器的地址返回给用户
用户向缓存服务器发起请求。如果缓存服务器上没有用户想要的内容,而区域均衡设备依然将它分配给了用户,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器将内容拉到本地。
3. 浏览器向 Web 服务器发送 HTTP 请求
重点在TCP连接建立的过程,三次握手,详细过程在另一篇文章写(TODO TCP三次握手,四次挥手,TCP时延),这里就带过
- 浏览器向服务器发送建立连接的请求(SYN = 1, seq = x)
- 服务器响应并告诉浏览器我收到了你建立连接的请求(SYN = 1, ACK = 1, seq = y,ack = x+1)
- 浏览器响应并告诉服务器,我收到了你的确认消息,接下来可以开始发送数据了(ACK = 1,seq = x+1,ack = y+1)
4. 服务器收到请求,进行处理并返回HTTP响应
状态码:
- 1xx:信息性状态码,表示服务器已经接受了客户端请求,客户端可以继续发送请求
- 2xx:成功状态码,表示服务器已经成功接收到进行并进行了处理
- 3xx:重定向状态码
- 301:永久性重定向
- 302:暂时性重定向
- 304:缓存——TODO 缓存文章
- 4xx:客户端错误状态码,表示客户端有错误
- 401:请求语法格式有误
- 401:请求未授权,该状态代码必须与 WWW-Authenticate 报头域一起使用
- 403:服务器收到请求,但是拒绝提供服务
- 404:Not Found
- 5xx:服务端错误
301 和 302 的区别:
301为永久性重定向,302为暂时性重定向
- 对于浏览器而言
- 301:浏览器会把这个重定向缓存起来,下一次就不查询,直接请求重定向之后的网址(类似强缓存)
- 302:只是暂时性的,所以浏览器每次都会先去请求一次原网址
- 搜索引擎的表现:
- 301:类似继承遗产,旧网址的搜索排名会直接转移给新网址,而且搜索引擎收录的会换成 新的网址对应新网址的内容
- 302:搜索排名不会转移,旧的网址对应新的内容
5. 浏览器显示 html
构建DOM树、构建CSSOM树 -> 构建 render 树 -> 布局 render 树
CSSOM树和DOM树的构建是同步的,但是CSS树的构建会阻塞 render 树的构建(否则样式突然出现也很惊吓),所以我们通常会把 css 放在代码html开头,让浏览器尽可能早地开始构建CSS树
而DOM树的构建和 js 代码的加在执行也是互斥的,当浏览器在解析DOM树的过程中发现了 script 标签,那么它会停止DOM树的构建,加载js代码并执行完毕之后,再重新开始DOM树的构建。
如果在script标签之前有一个外联的 css link 标签,那么构建过程会变成:
1. 构建DOM树
2. 遇到外联 link标签
3. fetch link资源,同时构建DOM树
4. 遇到 script 标签
5. 停止DOM树构建,fetch script资源
6. 等待第3步骤中的CSS资源fetch回来,并且等待CSSOM树构建完成(这里 CSSOM树的构建阻塞的 js 代码的**执行**)
7. 执行 js 代码
8. 继续构建DOM树不管是 JS的加载与执行 阻塞 DOM树的构建,还是 CSSOM 的构建阻塞 JS 的执行,都是符合浏览器的行为逻辑的,因为 js 是有可能会操作 DOM 节点 和 CSS 节点的,那么这种阻塞行为其实就是为了 保证 js 代码执行的正确性
script 标签的几种不同类型可能会有所不同
- async:异步,js 的加载不会阻塞DOM树的构建,js 一旦加载完毕,那么DOM树构建立即停止,开始执行 js代码,js代码执行完毕之后再重新开始构建DOM树
- defer:延迟,等待DOM树构建完成之后才会加载执行 js 代码
- 普通的script标签:js 的加载执行 都会阻塞 DOM 树的构建
js 代码对 CSS 和 DOM 的修改,其实是可能会触发浏览器的 重排和 重绘的,另开一篇文章讲解
TODO:浏览器重排重绘、浏览器层解析,composite过程
参考:
更快地构建DOM: 使用预解析, async, defer 以及 preload)
TODO
- TCP 三次握手、四次挥手、TCP时延原因
- 缓存
- 浏览器重排重绘、浏览器 层解析、composite过程